



I. Introduction▲
On appelle expression régulière une chaîne de caractères représentant un ensemble de chaînes de caractères.
Ainsi la chaîne 'abc', considérée comme expression régulière, représente un ensemble contenant un seul élément, la chaîne 'abc'. Chacun des trois caractères se représente lui-même.
I-A. Classes de caractères▲
Plus intéressante, l'expression régulière '[abc]' représente l'ensemble des chaînes constituées d'un seul caractère appartenant à l'ensemble ['a', 'b', 'c']. Ajoutons que les trois caractères 'a', 'b' et 'c' étant consécutifs dans l'alphabet, notre expression régulière aurait pu s'écrire '[a-c]', de même qu'en Pascal, on pourrait écrire ['a'..'c'] au lieu de ['a', 'b', 'c'].
À la différence des lettres de l'alphabet qui se représentent simplement elles-mêmes, les crochets et le trait d'union sont donc des caractères affectés d'une signification spéciale, que nous venons de voir. Pour que ces caractères spéciaux (qu'on appelle aussi métacaractères) soient traités comme des caractères ordinaires, c'est-à-dire interprétés littéralement, il faut les « échapper », comme dit l'anglais, en les faisant précéder d'une barre oblique inversée : '\[', '\]', '\-'. La barre oblique inversée est donc elle aussi un métacaractère.
Un autre caractère spécial dont il faut parler à cet endroit, c'est l'accent circonflexe. Lorsqu'il est placé immédiatement après un crochet ouvrant, il signifie la négation ou l'exclusion. Par exemple la classe '[^0-9]' contient tous les caractères qui ne sont pas des chiffres.
I-B. Classes prédéfinies▲
La barre oblique inversée sert aussi à donner une signification spéciale à des caractères qui par défaut sont interprétés littéralement.
Par exemple la lettre 'd', précédée d'une barre oblique inversée, représente la classe des chiffres (digits en anglais). Les trois expressions suivantes sont donc synonymes : '[0123456789]', '[0-9]', '\d'.
Un utilisateur averti des expressions régulières en Perl me faisait remarquer que dans les versions récentes de Perl, ces trois expressions ne sont plus synonymes, car la classe '\d' comprend désormais les chiffres de tous les alphabets, et non pas seulement ceux de l'alphabet latin.
Voici un tableau contenant toutes les classes prédéfinies.
|
Notation |
Sens |
Notation équivalente |
|
\a |
Cloche |
\x07 |
|
\d |
Chiffre |
[0-9] |
|
\e |
Échappement |
\x1B |
|
\f |
Nouvelle feuille |
\x0C |
|
\n |
Nouvelle ligne |
\0A |
|
\r |
Retour chariot |
\0D |
|
\s |
Espace (au sens large) |
[ \t] |
|
\t |
Tabulation |
\x09 |
|
\v |
Tabulation verticale |
\x0B |
|
\w |
Caractère alphanumérique (y compris '_') |
[A-Za-z0-9_] |
|
. |
Tous les caractères (sauf #13 et #10) |
[^\r\n] |
Notons que si nous remplaçons 'a', 'd', 'e' ou l'une des autres lettres par une majuscule, l'expression désigne alors l'ensemble des caractères n'étant pas la cloche, un chiffre, etc. Ainsi la classe '\D' est équivalente à la classe '[^0-9]' que nous avons vue tout à l'heure.
Le point est une classe de caractères à utiliser avec précaution : elle contient tous les caractères, à l'exception des caractères Retour chariot (#13) et Nouvelle ligne (#10).
La barre oblique inversée sert encore à former l'expression '\b' qui désigne, non pas une classe de caractères, mais le début ou la fin d'un mot, entendu comme séquence de caractères alphanumériques. C'est ce qu'on appelle une ancre.
I-C. Quantificateurs▲
Puisque nous savons maintenant comment désigner des ensembles de caractères, voyons comment noter le nombre de caractères attendus. Nous avons vu, sans le remarquer jusqu'ici, que par défaut c'est le nombre un.
Pour indiquer un autre nombre, ou même un intervalle, on peut se servir des accolades, mais aussi des caractères '+', '*', et '?'. Les accolades permettent d'indiquer un nombre exact de caractères, ou un intervalle exact. Le symbole '+' veut dire « une fois ou plus ». L'étoile veut dire « zéro fois ou plus ». Le point d'interrogation veut dire « zéro ou une fois ».
Par exemple, l'expression '\d{2}' veut dire « deux chiffres » ; '\d{2,4}' veut dire « de deux à quatre chiffres » ; '\d{2,}' veut dire « deux chiffres ou plus ». L'expression '\d+' veut dire « un chiffre ou plus » ; '\d*' veut dire « zéro chiffre ou plus » ; '\d?' veut dire « zéro chiffre ou un ».
Par défaut, les opérateurs '+', '*', et '?' sont gourmands (greedy en anglais), c'est-à-dire que la recherche renvoie non pas la première correspondance trouvée, mais la plus longue. Cela a souvent son importance. Pour changer ce comportement, autrement dit pour rendre les opérateurs paresseux (lazy), il faut les faire suivre d'un point d'interrogation : '+?', '*?', '??'.
I-D. Autres opérateurs▲
Les parenthèses sont également des caractères spéciaux : elles servent à délimiter des groupes de caractères, par exemple pour y appliquer des quantificateurs. Ainsi l'expression '(abc)?def' désigne un ensemble contenant deux éléments, les chaînes 'abcdef' et 'def'. Le point d'interrogation rend le groupe 'abc' facultatif.
Les parenthèses peuvent aussi être utilisées en combinaison avec la barre verticale, qui signifie « ou ». Par exemple l'expression 'a(b|c)d' désigne un ensemble contenant les chaînes 'abd' et 'acd'.
Enfin, les caractères '^' et '$' signifient respectivement le début et la fin de la chaîne. Nous allons voir dans un instant quelle est l'utilité de ces caractères. Mais oui, vous avez raison, cela fait deux significations différentes pour l'accent circonflexe. Suivant l'endroit où on le place, il ne sera pas interprété de la même façon, et cela vaut aussi pour les autres caractères.
I-E. Exercices▲
On veut s'assurer qu'une chaîne de caractères donnée représente une année comprise entre '1900' et '2999'. Proposez une expression régulière appropriée.
On veut s'assurer qu'une chaîne de caractères donnée est un nombre à six chiffres hexadécimaux précédé du symbole '$'. Proposez une expression régulière appropriée.
On veut extraire d'une chaîne tout ce qui précède la première virgule. Proposez une expression régulière appropriée.
II. Vérifier qu'une chaîne appartient à un ensemble▲
Il est temps à présent de faire connaissance avec l'unité RegularExpressions. Cette unité, apparue avec Delphi XE, va nous permettre d'effectuer diverses opérations sur des chaînes de caractères.
La plus simple de ces opérations est celle qui consiste à déterminer si telle chaîne appartient à tel ensemble.
II-A. La fonction IsMatch▲
La fonction dont nous avons besoin pour cela est la fonction IsMatch. Elle peut être appelée directement, avec deux chaînes de caractères comme arguments : le sujet (la chaîne à étudier) et l'expression régulière.
program IsMatch1;
{$APPTYPE CONSOLE}
uses
RegularExpressions;
begin
WriteLn(TRegEx.IsMatch('bonjour', '\w')); // un caractère alphanumérique
WriteLn(TRegEx.IsMatch('bonjour', '\w+')); // un ou plusieurs caractères alphanumériques
WriteLn(TRegEx.IsMatch('bonjour', '\w*')); // zéro ou plus
WriteLn(TRegEx.IsMatch('bonjour', '\w{7}')); // sept
WriteLn(TRegEx.IsMatch('bonjour', '[a-z]{7}')); // sept minuscules
WriteLn(not TRegEx.IsMatch('bonjour', '\d')); // un chiffre
WriteLn(not TRegEx.IsMatch('bonjour', '\s')); // un espace au sens large (équivalent à '[0-9]')
WriteLn(TRegEx.IsMatch('bonjour', '\D')); // un caractère qui n'est pas un chiffre
ReadLn;
end.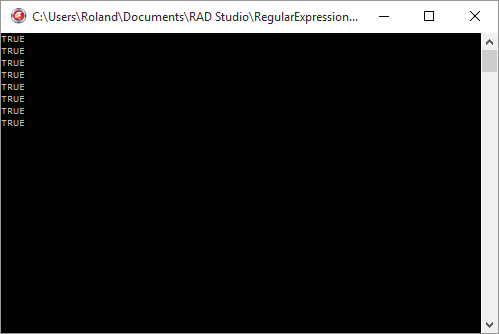
Comme vous l'avez remarqué si vous avez regardé de près le code ci-dessus, la fonction IsMatch vérifie seulement qu'une partie au moins de la chaîne passée comme premier argument appartient à l'ensemble représenté par l'expression régulière.
Si l'on veut s'assurer que la chaîne entière appartient à l'ensemble, il faut utiliser les opérateurs '^' et '$', qui signifient respectivement le début de chaîne et sa fin.
WriteLn(TRegEx.IsMatch('bonjour', '\w')); // TRUE
WriteLn(not TRegEx.IsMatch('bonjour', '^\w$')); // TRUEDans 'bonjour', il y a plusieurs caractères alphanumériques, mais il n'y a pas qu'un seul caractère entre le début et la fin de la chaîne.
II-B. Exercice▲
Écrire trois programmes vérifiant vos réponses aux trois exercices de la première partie.
III. Extraire d'une chaîne des groupes de caractères▲
III-A. Exemple▲
Imaginons que nous voulions, non seulement vérifier qu'une chaîne donnée appartient à un ensemble, mais aussi extraire de cette chaîne certains groupes de caractères. Disons par exemple que nous voulons extraire les groupes de chiffres d'une chaîne contenant une date, comme '26/09/2015'.
program Group1;
{$APPTYPE CONSOLE}
uses
SysUtils, RegularExpressions;
const
SUBJECT = '26/09/2015';
PATTERN = '(\d{2})/(\d{2})/(\d{4})';
var
expr: TRegEx;
match: TMatch;
group: TGroup;
begin
expr := TRegEx.Create(PATTERN);
match := expr.Match(SUBJECT);
if match.Success then
for group in match.Groups do
WriteLn(Format('TGroup.Index=%d TGroup.Value="%s"', [group.Index, group.Value]));
ReadLn;
end.
Nous avons utilisé dans notre expression régulière des parenthèses pour délimiter les groupes de caractères à extraire, puis nous avons utilisé la fonction Match. Soit dit en passant, nous n'avons pas vérifié que les chiffres extraits formaient en effet une date valide. L'expression utilisée ne tient pas compte du fait qu'il n'y a que 31 jours au plus dans le mois, 12 mois dans l'année, etc. Une vérification complète devrait même tenir compte des années bissextiles, mais il est peu probable que cela soit faisable par les expressions régulières !
III-B. Groupes nommés▲
Nous pouvons également nommer les groupes. Pour nommer un groupe, il faut insérer juste après la parenthèse ouvrante les caractères '?<nom>'.
program Group2;
{$APPTYPE CONSOLE}
uses
SysUtils, RegularExpressions;
const
SUBJECT = '26/09/2015';
PATTERN = '(' + '?<day>' + '\d{2})/(' + '?<month>' + '\d{2})/(' + '?<year>' + '\d{4})';
var
group: TGroup;
match: TMatch;
regEx: TRegEx;
begin
regEx := TRegEx.Create(PATTERN, []);
match := regEx.Match(SUBJECT);
if match.Success then
begin
group := match.Groups['year'];
WriteLn(group.Value);
end;
ReadLn;
end.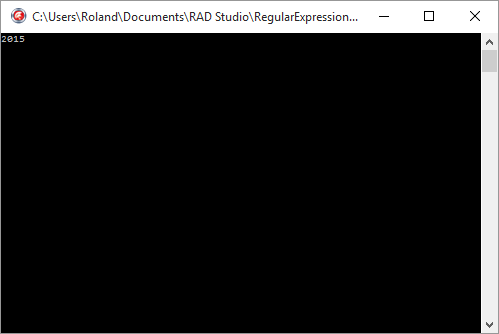
III-C. Parenthèses non capturantes▲
Quelquefois on a besoin de délimiter un groupe de caractères, mais on n'a pas besoin de capturer les caractères correspondants. Dans ce cas, pour ne pas donner de travail inutile au programme, on aura recours à des parenthèses non capturantes.
Imaginons par exemple qu'on veuille détecter dans un code source en Pascal les Write et les WriteLn, sans faire de différence entre les deux. On pourrait utiliser l'expression 'Write(Ln)?'. Mais de cette façon on capturerait à chaque fois ou une chaîne vide ou la chaîne 'Ln'. Cependant nous avons supposé qu'on ne voulait pas tenir compte de la différence entre Write et WriteLn. On utilisera donc l'expression suivante :
'Write(?:Ln)?'Les caractères '?:' ont été ajoutés immédiatement après la parenthèse ouvrante pour rendre les parenthèses non capturantes.
III-D. Exercice▲
Écrire un programme qui extrait les parties numériques d'une heure donnée sous la forme hh:mm, par exemple '10:29'. Le programme devra vérifier de la façon la plus stricte la validité de l'heure.
IV. Détecter des correspondances multiples▲
Il est possible de détecter les multiples groupes de caractères qui, dans une chaîne donnée, appartiennent à un même ensemble. Pour cela nous aurons besoin des fonctions Match, Success et NextMatch.
IV-A. La fonction NextMatch▲
L'exemple suivant détecte les groupes de caractères représentant des nombres.
program Match1a;
{$APPTYPE CONSOLE}
uses
SysUtils, RegularExpressions;
var
match: TMatch;
begin
match := TRegEx.Match('10 +10 0.5 .5', '\s*[-+]?[0-9]*\.?[0-9]+\s*');
while match.Success do
begin
WriteLn(match.Value);
match := match.NextMatch;
end;
ReadLn;
end.
IV-B. Le type TMatchCollection▲
La même opération peut être effectuée d'une autre façon : au moyen de la fonction Matches, laquelle renvoie un résultat de type TMatchCollection.
program MatchCollection1;
{$APPTYPE CONSOLE}
uses
SysUtils,
RegularExpressions;
var
expr: TRegEx;
collection: TMatchCollection;
i: Integer;
begin
expr.Create('\w');
collection := expr.Matches('abc');
for i := 0 to collection.Count - 1 do
with collection[i] do
WriteLn(Format('%d %d %d %s', [i, Index, Length, Value]));
ReadLn;
end.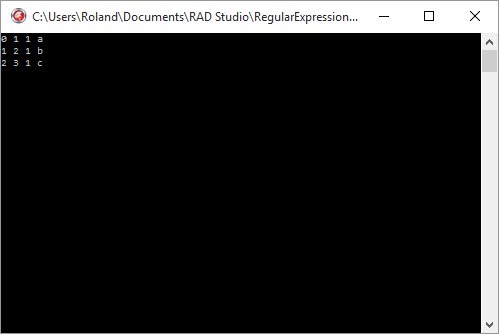
IV-C. Exercice▲
Écrire deux versions d'un programme qui extrait tous les chemins de la variable d'environnement PATH. La première version du programme utilisera la méthode NextMatch, la seconde version utilisera la méthode Matches.
V. Éclatement d'une chaîne▲
Voyons à présent comment éclater une chaîne au moyen d'une expression régulière, c'est-à-dire la découper selon une certaine règle et disposer les morceaux découpés dans un tableau.
V-A. Exemple▲
L'expression représente un groupe de caractères à traiter comme délimiteurs. Dans le cas le plus simple, c'est un seul caractère :
program Split1;
{$APPTYPE CONSOLE}
uses
SysUtils, RegularExpressions;
var
a: TArray<string>;
s: string;
i: integer;
begin
a := TRegEx.Split(GetEnvironmentVariable('PATH'), ';');
for s in a do
WriteLn(s);
a := TRegEx.Split('a b,c-d', '[ ,-]');
for i := 0 to High(a) do
WriteLn(a[i]);
ReadLn;
end.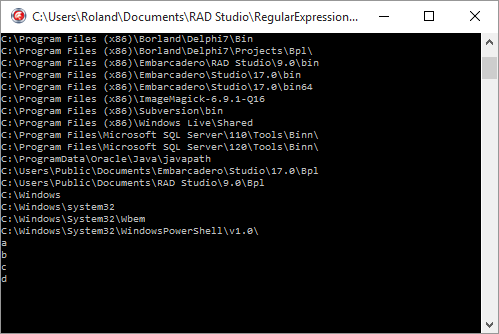
V-B. Exercice▲
Écrire un programme qui découpe le contenu de la variable d'environnement PATH en traitant comme délimiteurs les caractères ';' et '\'.
VI. Remplacement de groupes de caractères▲
L'opération suivante ressemble un peu à la précédente : au lieu de traiter certains groupes de caractères comme délimiteurs, nous les remplacerons, au moyen de l'expression Replace.
VI-A. Remplacement par une chaîne constante▲
program Replace1;
{$APPTYPE CONSOLE}
uses
RegularExpressions;
begin
WriteLn(TRegEx.Replace('WRITELN writeln', 'writeln', 'WriteLn', [roIgnoreCase]));
ReadLn;
end.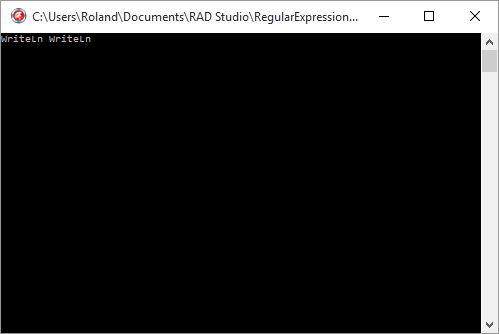
Comme vous le voyez, la fonction Replace admet quatre paramètres : la chaîne à traiter, l'expression régulière représentant les groupes à remplacer, la chaîne par laquelle ces groupes seront remplacés et enfin un ensemble d'options. Dans l'exemple ci-dessus, on a utilisé (sans aucune utilité d'ailleurs) l'option permettant d'obtenir un remplacement qui ne tienne pas compte de la casse des groupes à remplacer.
VI-B. Remplacement par une chaîne composée▲
Au lieu de remplacer les groupes par une chaîne constante, on peut les remplacer par une chaîne variable, composée d'éléments des groupes détectés.
program Replace2;
{$APPTYPE CONSOLE}
uses
RegularExpressions;
var
expr: TRegEx;
begin
expr := TRegEx.Create('(\w+)\s(\w+)');
WriteLn(expr.Replace('abc def', '\2 \1'));
ReadLn;
end.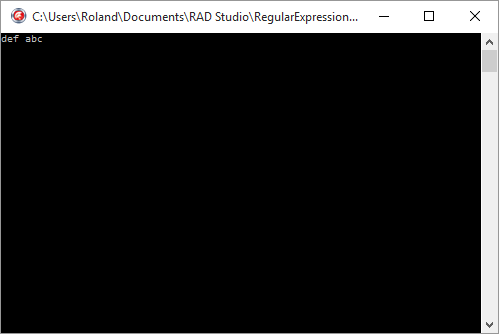
Dans la chaîne '\2 \1', la barre oblique inversée suivie d'un chiffre représente l'élément capturé qui devra être inséré à cette place dans la chaîne de remplacement. Ainsi, '\1' signifie « le premier élément capturé ».
Pratique, non ? Mais ce n'est pas tout. La chaîne de remplacement peut même être le résultat d'une fonction recevant comme arguments les éléments capturés.
VI-C. Remplacement par le résultat d'une fonction▲
Supposons que nous voulions valider une chaîne représentant une position donnée d'une partie d'échecs. La chaîne devra être conforme à la notation standard, à savoir la notation FEN (Forsyth-Edwards Notation). Voici la chaîne FEN correspondant à la position initiale d'une partie de jeu d'échecs :
'rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1'Comme on le voit, l'occupation des lignes de l'échiquier est représentée par des groupes de caractères contenant des lettres (les pièces) et des chiffres (le nombre de cases vides consécutives). Nous devons nous assurer que le nombre total de cases pour chaque ligne de l'échiquier est bien égal à huit, et pour ce faire nous décidons de remplacer les chiffres par des caractères répétés autant de fois qu'il y a de cases vides.
type
TFENValidator = class
function ReplaceWith(const aMatch: TMatch): string;
function ExpandRow(const aRow: string): string;
function IsFEN(const aStr: string): boolean;
end;
function TFENValidator.ReplaceWith(const aMatch: TMatch): string;
const
EMPTY_SQUARE_SYMBOL = '-';
begin
result := StringOfChar(EMPTY_SQUARE_SYMBOL, StrToInt(aMatch.Groups.Item[1].Value));
end;
function TFENValidator.ExpandRow(const aRow: string): string;
begin
with TRegEx.Create('([1-8])') do
result := Replace(aRow, ReplaceWith);
end;
function TFENValidator.IsFEN(const aStr: string): boolean;
var
a,
b: TStringList;
expr: TRegEx;
i: integer;
s: string;
begin
a := TStringList.Create;
b := TStringList.Create;
b.Delimiter := '/';
b.StrictDelimiter := TRUE;
a.DelimitedText := aStr;
result := (a.Count = 6);
if not result then
Exit;
b.DelimitedText := a[0];
result := result and (b.Count = 8);
if not result then
Exit;
expr.Create('^[1-8BKNPQRbknpqr]+$');
for i := 0 to b.Count - 1 do
begin
s := ExpandRow(b[i]);
{WriteLn(s);}
result := result and expr.IsMatch(b[i]) and (Length(s) = 8);
end;
result := result and TRegEx.IsMatch(a[1], '^(w|b)$');
result := result and TRegEx.IsMatch(a[2], '^([KQkq]+|\-)$');
result := result and TRegEx.IsMatch(a[3], '^([a-h][36]|\-)$');
expr.Create('^\d+$');
result := result and expr.IsMatch(a[4]) and (StrToInt(a[4]) >= 0);
result := result and expr.IsMatch(a[5]) and (StrToInt(a[5]) >= 1);
end;Voici un autre exemple de remplacement par fonction. C'est un programme qui cherche dans une chaîne de caractères des variables à remplacer par leur valeur. Les variables sont notées suivant la syntaxe utilisée pour les variables d'environnement comme %date% ou %username%. La fonction renvoyant la chaîne à substituer tirera ses résultats d'un dictionnaire.
program Replace3b;
{$APPTYPE CONSOLE}
uses
System.SysUtils,
System.Classes,
System.RegularExpressions;
type
TExpander = class
fDictionary: TStrings;
constructor Create(aDictionary: TStrings);
function ReplaceWith(const aMatch: TMatch): string;
function Expand(const s: string): string;
end;
constructor TExpander.Create(aDictionary: TStrings);
begin
fDictionary := aDictionary;
end;
function TExpander.ReplaceWith(const aMatch: TMatch): string;
begin
result := fDictionary.Values[aMatch.Groups.Item[1].Value];
end;
function TExpander.Expand(const s: string): string;
var
expr: TRegEx;
begin
expr.Create('%(.+)%');
result := expr.Replace(s, ReplaceWith);
end;
var
dictionary: TStrings;
expander: TExpander;
begin
dictionary := TStringList.Create;
expander := TExpander.Create(dictionary);
dictionary.Values['REPERTOIRE_PROJET'] := ExtractFileDir(ParamStr(0));
WriteLn(expander.Expand('%REPERTOIRE_PROJET%'#13#10'%REPERTOIRE_PROJET%'));
dictionary.Free;
expander.Free;
ReadLn;
end.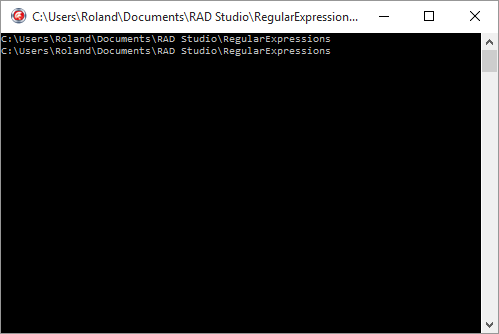
VI-D. Exercice▲
Écrire un programme qui remplace les multiples occurrences d'une date sous la forme jj/mm/aaaa par une date de la forme mm/jj/aaaa.
VII. Expressions alternatives▲
Rassurez-vous, nous avons pratiquement fini notre tour des fonctions de l'unité RegularExpressions. Si vous avez encore une minute, je vous propose un dernier exemple montrant comment on peut utiliser des expressions alternatives, pour savoir si une chaîne donnée appartient à tel ensemble, ou à un tel autre, ou à un troisième, etc.
VII-A. Exemples▲
Dans le langage des expressions régulières, c'est le caractère '|' qui symbolise cette alternative.
program Alternative1;
{$APPTYPE CONSOLE}
uses
SysUtils, RegularExpressions;
const
SAMPLE: array[0..10] of string = (
'*ABORG-001360',
'?CASTELO 1419-002370',
'*EX/MINOU1424-412380',
'*RUBAN-003001',
'1234578011230',
'3760162052329',
'1456441001360',
'AAAAAAA',
'*AAAAA-001',
'*AAAAAA001360',
'123121212'
);
const
PATTERN1 = '^[*?]([^-]{1,15})-(\d{3})(\d{3})$';
PATTERN2 = '^(123\d{10})$';
PATTERN3 = '^(\d{13})$';
PATTERN = PATTERN1 + '|' + PATTERN2 + '|' + PATTERN3;
var
group: TGroup;
expr: TRegEx;
match: TMatch;
i: integer;
begin
expr := TRegEx.Create(PATTERN);
for i := Low(SAMPLE) to High(SAMPLE) do
begin
match := expr.Match(SAMPLE[i]);
if match.Success then
begin
Write(i);
for group in match.Groups do
Write(' "', group.Value, '"');
WriteLn;
end;
end;
ReadLn;
end.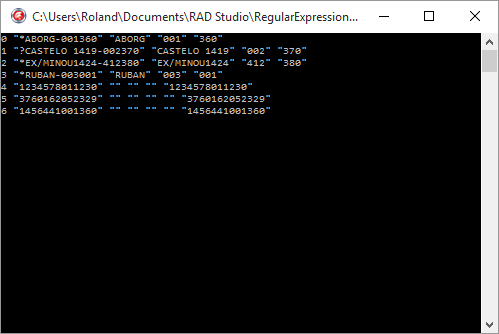
Le code ci-dessus affiche tous les résultats sans les analyser. Si l'on veut savoir à laquelle des expressions régulières correspond tel groupe de caractères, on pourra procéder de la façon suivante :
procedure ShowResult(aGroupName: string);
begin
WriteLn(Format(' %s = "%s"', [aGroupName, match.Groups[aGroupName].Value]));
end;
begin
expr := TRegEx.Create(PATTERN);
for i := Low(SAMPLE) to High(SAMPLE) do
begin
WriteLn('SAMPLE[', i, ']');
match := expr.Match(SAMPLE[i]);
if match.Success then
begin
case match.Groups.Count of
4: begin
ShowResult('nom1');
ShowResult('nom2');
ShowResult('nom3');
end;
5: ShowResult('nom4');
6: ShowResult('nom5');
end;
end;
end;
ReadLn;
end.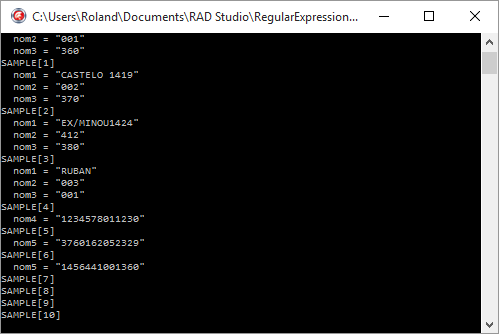
On remarque dans l'exemple ci-dessus que lorsque la chaîne étudiée correspond à la troisième expression alternative, la variable match.Groups.Count vaut 6, parce que le groupe capturé correspond à la sixième sous-expression entre parenthèses.
Ce comportement peut être modifié, de telle sorte que le comptage des groupes soit fait séparément pour chacune des expressions alternatives, au lieu d'être un comptage global. Pour cela, il faudra utiliser l'expression suivante :
PATTERN = '(?|' + PATTERN1 + '|' + PATTERN2 + '|' + PATTERN3 + ')';Attention, le comptage pour chaque expression alternative commencera à deux, à cause des parenthèses que nous avons ajoutées. Ces parenthèses produiront une capture supplémentaire (et inutile).
VII-B. Exercice▲
Écrire un programme qui utilise des expressions alternatives pour savoir si une chaîne donnée est une date (de la forme jj/mm/aaaa), une heure (de la forme hh:mm) ou autre chose.
VIII. Unicode▲
L'unité RegularExpressions supporte l'Unicode. Voici une expression régulière représentant les lettres capitales de l'alphabet grec :
program Unicode6;
{$APPTYPE CONSOLE}
uses
System.RegularExpressions,
Vcl.Dialogs;
var
s: UnicodeString;
match: TMatch;
begin
s := 'ΙΧΘΥΣ';
match := TRegEx.Match(s, '[Α-Ω]{5}');
ShowMessage(match.Value);
end.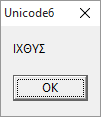
IX. Conclusion▲
L'unité RegularExpressions est basée sur l'unité RegularExpressionsCore qui, sauf le nom, est identique à l'unité PerlRegEx de Jan Goyvaerts.
uses
{$IF CompilerVersion >= 22.0}
RegularExpressionsCore;
{$ELSE}
PerlRegEx; (* http://www.regular-expressions.info/download/TPerlRegEx.zip *)
{$IFEND}L'unité PerlRegEx est, elle, basée sur la bibliothèque PCRE (Perl Compatible Regular Expressions) de Philip Hazel.
Si vous souhaitez en savoir plus sur la syntaxe des expressions régulières, vous pouvez consulter le tutoriel de Jan Goyvaerts : Regular Expressions. Vous pouvez télécharger les exemples commentés dans cet article (et quelques autres) : Exemples.
La solution des exercices se trouve dans le dossier Solutions. Le dossier RegularExpressionsCore contient des exemples d'utilisation de l'unité RegularExpressionsCore ou PerlRegEx.
Les exemples ont été testés avec Delphi XE2.
Je remercie les membres du forum qui m'ont permis de reproduire leurs exemples, ainsi que les relecteurs de cet article : gvasseur58, Alcatîz, Lolo78, ClaudeLELOUP, pierruel et f-leb.